
经过一系列测试,从创意写作到复杂的教学,DeepSeek-R1 的综合实力能够与 OpenAI 的付费高端模型相媲美。这表明即使采取性价比路线,也能在 AI 竞技场中取得优异表现。


DeepSeek 发布其开放权重的 R1 推理模型仅一周时间,便多次震惊海内外。不仅训练成本仅为 OpenAI 最先进模型的一小部分,性能还能与其媲美。为了验证其实用性,科技媒体资深编辑决定将 DeepSeek 的 R1 模型与 OpenAI 的 ChatGPT 模型进行对比,重点在于模拟用户可能提出的日常问题。
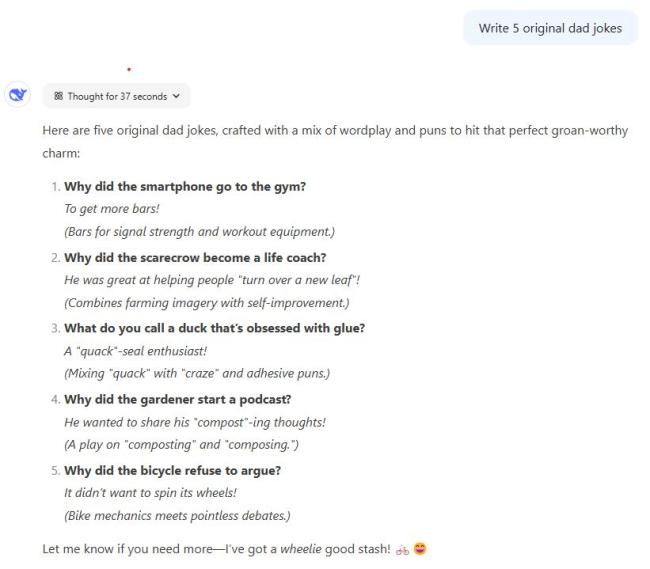
测试中,DeepSeek 的每个回答都与 ChatGPT 的 20 美元/月的 o1 模型和 200 美元/月的 o1 Pro 模型进行对比。测试涵盖创意写作、数学、指令遵循等领域,并考虑了模型回答的正确性和主观质量因素。结果显示,在八项测试中,DeepSeek:o1:o1 Pro 的比拼结果为 5:2:4。

在老爸笑话生成任务中,三个模型都认真对待了原创要求。尽管有一些笑话在网上能找到类似例子,但总体上 DeepSeek R1 表现更出色,尤其是自行车笑话和吸尘器乐队笑话。
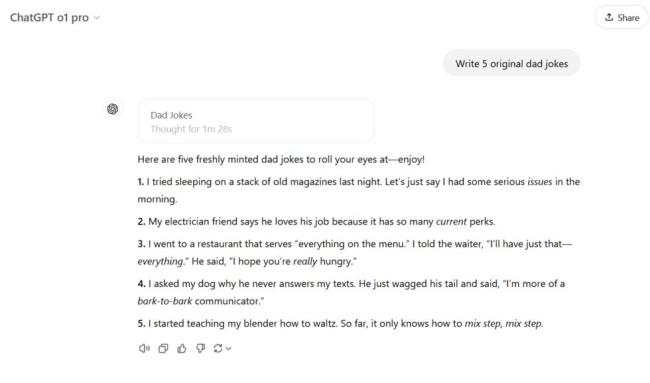
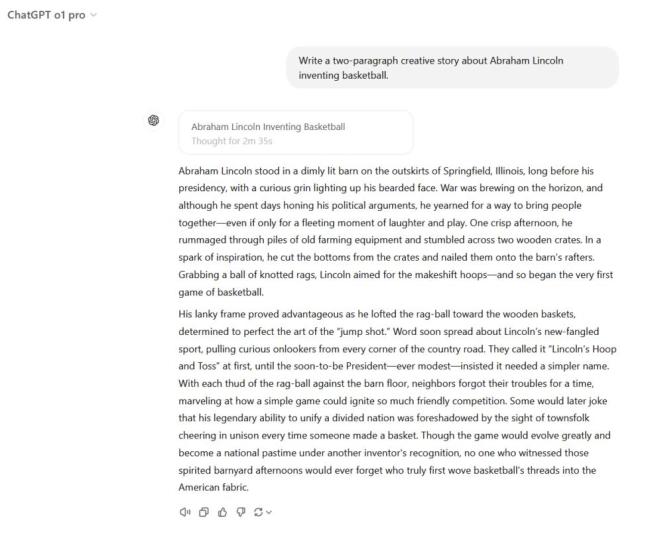
关于亚伯拉罕·林肯发明篮球的故事创作,DeepSeek R1 以荒诞方式回应,加入了许多有趣细节,赢得了团队青睐。而 ChatGPT o1 和 o1 Pro 则较为传统,尽管后者尝试了一些创新元素。
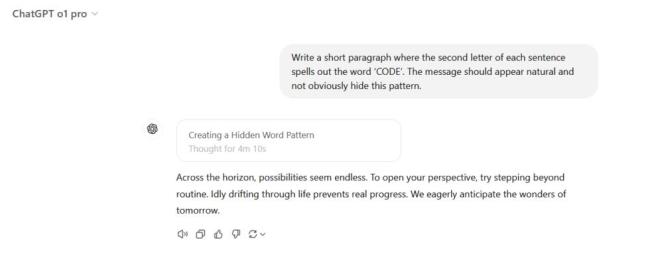
另类藏头诗任务中,DeepSeek R1 和 ChatGPT o1 都未能正确理解提示,使用了每句话的第一个字母而非第二个字母。只有 ChatGPT o1 Pro 成功完成了任务。
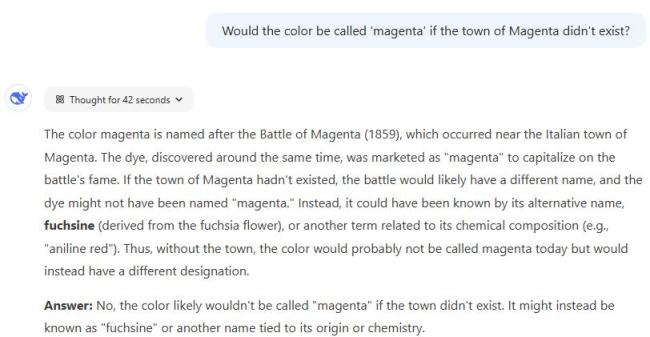
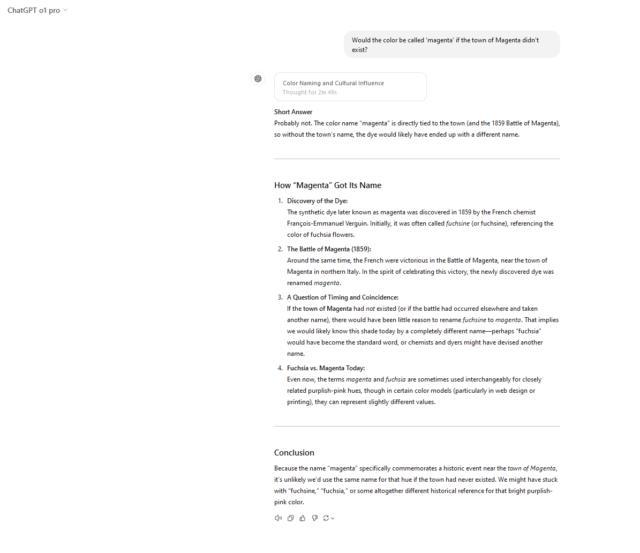
历史颜色命名问题上,三个模型都正确指出了“品红”名称的由来及其相关背景。ChatGPT o1 Pro 在风格上略胜一筹,提供了简洁且详细的解释。
在挑战巨型质数的任务中,DeepSeek R1 是唯一一个给出精确答案的模型,引用了公开计算结果。而 ChatGPT 模型则表示没有权威项目定位过该数值,只能估算大致范围。

赶飞机的时间表制定任务中,三款模型都算对了基础时间。DeepSeek R1 提供了更多实用建议,如提前准备行李和早餐,并强调了交通延误的风险。

追踪球的下落任务中,所有模型都能正确推理出球的位置。DeepSeek R1 特别指出杯子无密封盖这一前提,增加了趣味性。
复数集合测试中,三个模型均生成了有效回答,但 DeepSeek R1 在计算总位数时出现错误。最终两款 ChatGPT 模型因未出现算术错误而胜出。
DeepSeek-R1 展现了强大的综合实力,尤其是在某些特定任务中表现出色。这证明了通过正确的策略,性价比高的方法同样可以在 AI 竞技场中脱颖而出。

主题测试文章,只做测试使用。发布者:广众网,转转请注明出处:https://www.zmdnky.org.cn/article/7840.html